The Challenge in Computational Drug Discovery
For a summer internship, then later as a contractor during the school year, I developed an internal web platform for Architect Therapeutics. My first task was to develop an algorithm for identifying drug hits from mass spec readings. Once this was done, researchers needed a way to run this, along with other algorithms, and view the results. So, I built a platform to manage and orchestrate the various jobs. This was developed with constant feedback and suggestions from the researchers, and it gave me a good understanding of systems design, especially when working with others and planning for future features.

System Architecture & Design
The platform implements a distributed microservices architecture designed for scalability, reliability, and maintainability. Each component serves a specific purpose while maintaining loose coupling through well-defined APIs, creating a system that can grow with the research team's needs.
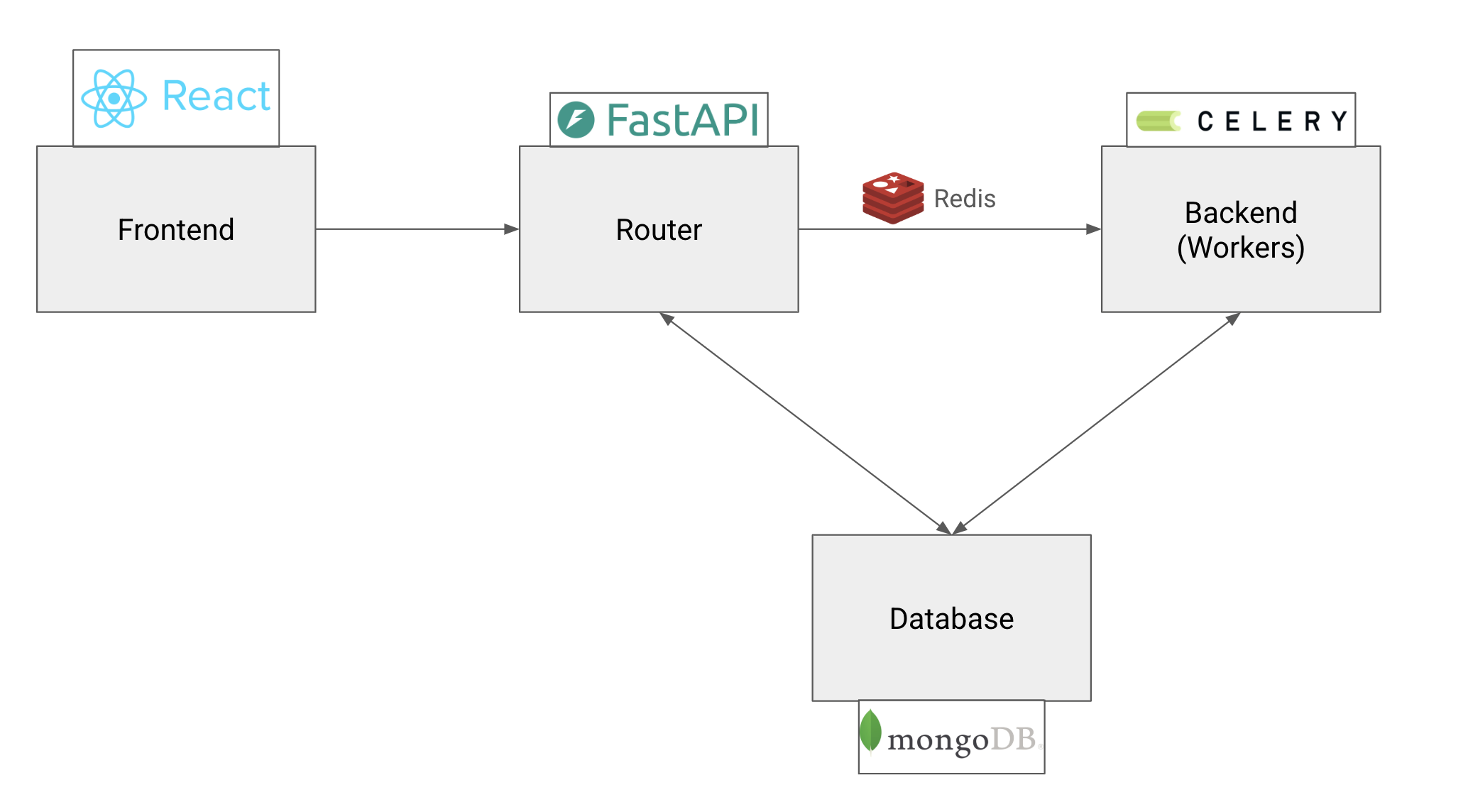
At the frontend, a React application built with TypeScript provides researchers with an intuitive interface for managing their computational workflows. It is a SPA with routes and page navigation, run using Vite. The backend centers around a FastAPI router that orchestrates communication between all system components. This high-performance Python framework handles authentication, manages API requests, and ensures secure access to computational resources. The RESTful design makes the system accessible to both human users through the web interface and automated tools through programmatic access.
The heart of the computational system lies in its distributed task processing architecture. Celery workers handle the execution of algorithms across multiple computing nodes, while Redis serves as both a message broker and caching layer. This design allows the platform to scale computational capacity dynamically based on demand, ensuring that researchers never have to wait for resources when conducting time-sensitive experiments. With Celery, jobs can run in parallel on the compute cluster asynchronously, allowing the researchers to complete other tasks or use other parts of the website while the jobs run.
Data Management and Computational Workflows
Central to the platform's effectiveness is data management. Designing a flexible and scalable database schema was a key challenge and required a significant rewrite after a few months of the original design to accommodate new features. MongoDB serves as the primary data store, chosen for its ability to handle the varied data structures along with relational data.
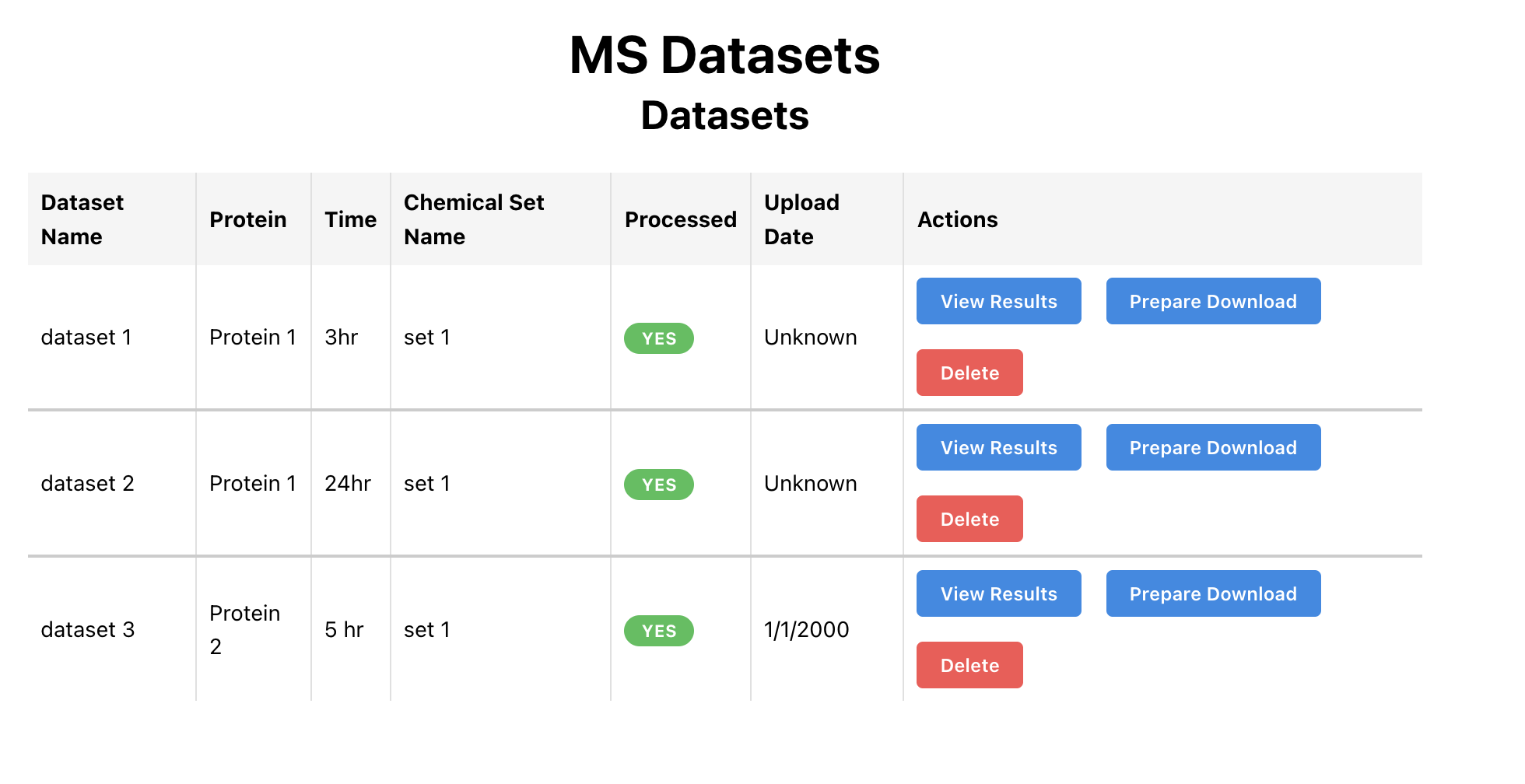
The platform's containerized architecture, built with Docker, ensures consistent execution environments. Because I was developing on a different machine than deployment, this was a crucial choice and saved a lot of pain. Each part of the system—the frontend, backend, database, and Celery workers—are all seperately containerized and can be rebooted or edited independently.
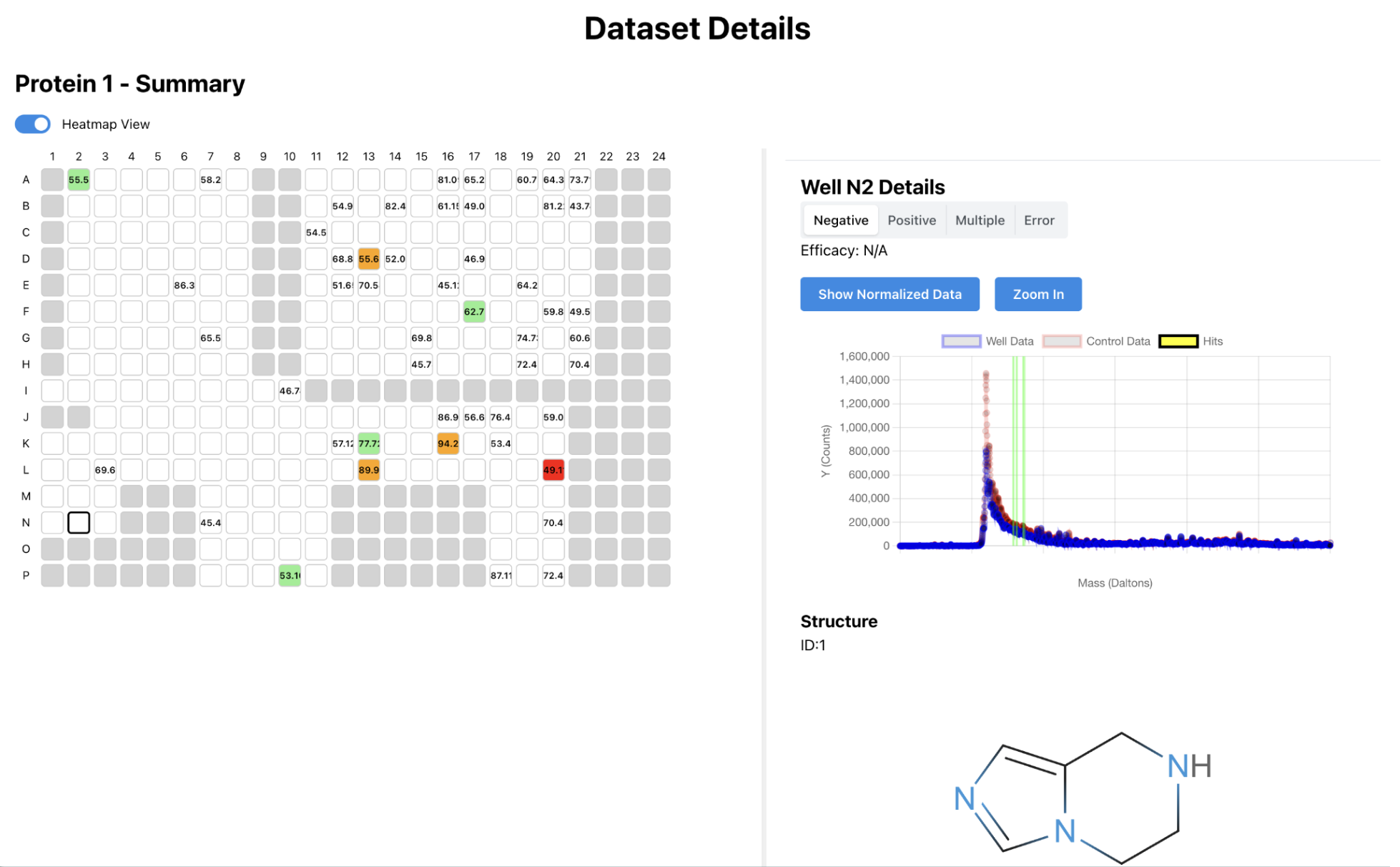
Production Impact
I built this platform independently from the ground up, architecting every component from the database schema to the distributed task processing system. Throughout development, I worked closely with the computational scientists, incorporating their feedback and expertise to ensure the platform would truly serve their research needs. This collaborative approach meant frequent design discussions and iterative refinements, transforming their workflow requirements into a robust technical solution.
The platform has since become the central hub for all computational research at Architect Therapeutics. What began as a summer internship project evolved into production infrastructure that the research team now depends on daily. The system handles everything from algorithm execution to data management, fundamentally changing how scientists interact with their computational resources. Rather than wrestling with manual job submissions and scattered data, researchers can now focus entirely on the scientific work that drives drug discovery forward.
Today, the platform continues to serve as the company's core computational infrastructure and is actively maintained by new employees who have taken over its stewardship. The modular architecture and documentation I developed have enabled smooth knowledge transfer, allowing the system to grow and evolve with the organization's expanding research needs. Seeing something I built from scratch become an enduring part of the company's technical foundation has been one of the most rewarding aspects of this project.